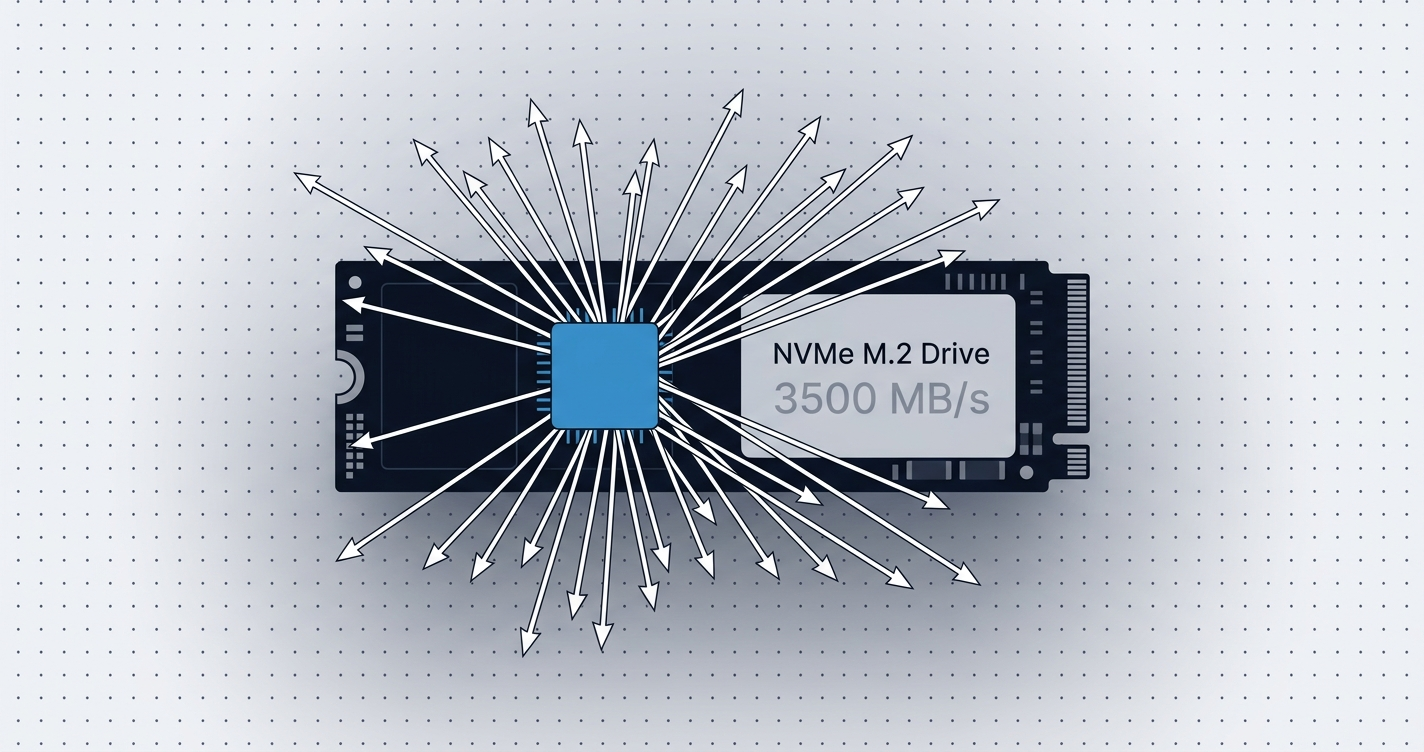
You buy a Crucial P3 4TB. 3,500 MB/s sequential read. Well-reviewed. Under $200. You install Nethermind. State sync starts, then stalls on the same block range for eight hours. Nothing in the logs suggests a network problem or a software bug. You run a storage benchmark: sequential read 3,400 MB/s, sequential write 3,000 MB/s. The drive is performing exactly as advertised.
The problem is that Ethereum nodes don’t do sequential I/O.
EIP-7870, updated in March 2026 (PR #11356, authored by Barnabas Busa), added explicit IOPS floors and benchmark commands to Ethereum’s hardware recommendations because the previous guidance (“get an NVMe”) was not a sufficiently precise specification.12 A Crucial P3 and a Samsung 990 Pro are both NVMe. One syncs Ethereum. One doesn’t. The ethereum node hardware requirements didn’t change; they were finally written down precisely enough to mean something.
Why Ethereum reads are not sequential
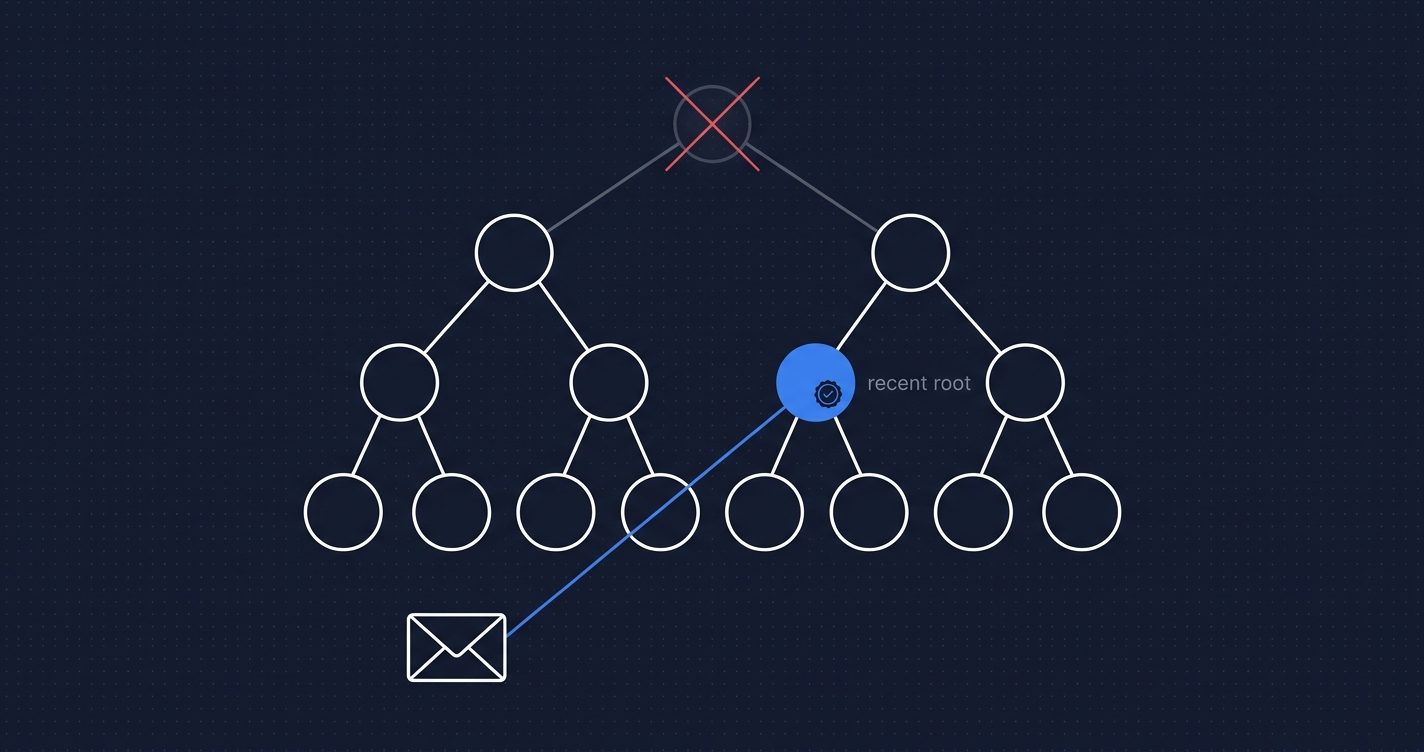
Ethereum’s state is stored in a Merkle Patricia Trie. Accessing a single account or storage slot requires traversing the trie from the root, following hashed node references at each branch.
Each step in that traversal is a random 4K disk read. The next node’s location is derived from the previous node’s hash. There is no spatial relationship between adjacent trie nodes on disk. A cold-cache read for a single account state lookup requires 15 to 30 random 4K reads in the worst case, depending on trie depth.
Contrast this with sequential I/O: video streaming, backup, large file transfers. In those workloads, the disk reads addresses in order, which is what both HDDs and the SLC write-cache optimization in consumer NVMe flash are designed for.
Ethereum’s access pattern is the opposite. Transactions read accounts scattered across the key space. The trie maps those keys through a series of hash-derived addresses with no locality. After the Merge, mainnet’s trie holds over 1.2 billion nodes. Each block execution traverses paths through that structure, not through adjacent sectors.
Sequential MB/s is essentially irrelevant for node performance. The spec sheet number most operators cite to verify a drive’s fitness is measuring the wrong thing.
What EIP-7870’s “realistic minimum” update changed
Before March 2026, EIP-7870 specified “NVMe M.2” storage without IOPS floors. After PR #11356, it specifies concrete minimums at the 4K block size:1
- Random 4K read IOPS: at least 50,000
- Random 4K write IOPS: at least 15,000
- Sequential read/write: at least 500 MB/s
- NVMe M.2 required; SATA explicitly insufficient
- DRAMless and QLC NAND explicitly warned against
The full hardware table:
| Role | Storage | RAM | CPU | Bandwidth |
|---|---|---|---|---|
| Full Node | 4 TB NVMe | 32 GB | 4c/8t, ~1k ST PassMark | 50 Mbps down / 15 up |
| Attester | 4 TB NVMe | 64 GB | 8c/16t, ~3.5k ST | 50 Mbps down / 25 up |
| Local Block Builder | 4 TB NVMe | 64 GB | 8c/16t (same) | 100 Mbps down / 50 up |
The EIP explains the intent directly: “It is possible to tune cache size in different clients to make it work, however we do not assume that the average user will do this.”1 These are practical deployment targets, not expert-tuned minimums.
The word “realistic” is doing real work in the update title. Previous informal guidance created a class of operators running nodes on hardware that looked compliant but couldn’t sustain the I/O pattern Ethereum actually uses.
The failure mode: QLC NAND and DRAMless controllers
QLC NAND (four bits per cell) has good sequential write performance because it uses an SLC write cache: a reserved pool of cells written in the faster single-bit mode. Sequential benchmarks hit that cache and look fast. But once the cache fills during a sustained random workload, write speed collapses to somewhere between 3,000 and 10,000 IOPS. The state sync workload is exactly that kind of sustained random workload.
DRAMless controllers lack an onboard DRAM buffer for the Flash Translation Layer (FTL) mapping table. The FTL maps logical block addresses to physical flash locations. Without DRAM, the controller reads the mapping from flash on every I/O operation, adding an extra read per write. Under Ethereum’s access pattern, this consistently produces IOPS below the floor.
Measured community data for common drives:3
| Drive | 4K Read IOPS | 4K Write IOPS | Passes 50K floor? |
|---|---|---|---|
| Crucial P3 4TB | 27,000 | 9,000 | No |
| Kingston NV2 | 24,000 | 8,000 | No |
| WD Green SN350 | 20,000 | 6,000 | No |
| Teamgroup MP44 | 28,400 | 9,500 | No |
| SK Hynix P41 Platinum 2TB | 99,000 | 33,000 | Yes |
| Samsung 990 Pro 4TB | 124,000 | 41,000 | Yes* |
| Sabrent Rocket 4 Plus 4TB | 149,000 | 49,000 | Yes |
| Kingston Fury Renegade 4TB | 211,000 | 70,000 | Yes |
*Samsung 990 Pro requires firmware 1B2QJXD7 or later to avoid thermal throttling issues.
The benchmark command EIP-7870 now recommends running before provisioning any node:
# Sequential read/write
fio --name=seq --filename=test --direct=1 --ioengine=libaio \
--iodepth=64 --bs=1M --size=4G --rw=readwrite
# Random 4K , the critical test
fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 \
--name=test --filename=test --bs=4k --iodepth=64 --size=4G \
--readwrite=randrw --rwmixread=75Run this on the actual device before installing a client. Sequential speed tests are not a substitute.
The latency dimension
IOPS is a throughput metric. Latency is the operational one.
The community-reported target for Geth’s p50 I/O latency during normal operation is approximately 300 microseconds.3 Two reference points against that target:
- AWS gp3 at 16,000 provisioned IOPS: 615 microseconds average latency (roughly 2x the target)
- Enterprise TLC NVMe under the same workload: 80 microseconds average latency (3.75x faster than gp3)
AWS gp3 caps at 16,000 provisioned IOPS, well below the 50,000-read floor in EIP-7870. Running an Ethereum node on gp3 block storage produces the same failure mode as a DRAMless consumer drive. If cloud storage is required, AWS io2 Block Express with provisioned IOPS is the correct option, at significantly higher cost.
The p99 latency metric operators should track is newPayloadVx quantile. If p99 exceeds 500ms during normal execution layer operation, the node risks missing attestation windows on mainnet or falling behind chain head on an L2.
Two environmental factors that degrade even compliant drives:
Temperature. Drives above 60°C throttle to reduce IOPS. Some drives reach 81°C without heatsinks in dense rack deployments. Monitor thermals and add heatsinks where needed.
Filesystem. Copy-on-write filesystems like btrfs or ZFS add significant write amplification. Community measurements have found roughly 6x write I/O overhead vs ext4 for the same node workload. Use ext4 for the state database volume.
For latency testing before commissioning a node:
sudo ioping -D -c 30 /dev/<ssd-device>Glamsterdam changes the access pattern, not the floor
EIP-7928 Block-Level Access Lists land in Glamsterdam, targeted for Q3 2026.4 BALs change how nodes access disk during block execution, which raises the question of whether EIP-7870’s IOPS floor still applies post-upgrade.
BALs expose every account and storage slot touched in a block upfront, with post-execution values. Before executing a block, a node can pre-fetch all required state from disk in parallel, rather than discovering storage dependencies during sequential execution.
The current pattern (execute, encounter a storage dependency, read from disk, stall) is replaced with a burst of parallel reads at block arrival, followed by in-memory execution. The I/O profile becomes more predictable and more cacheable.
But it doesn’t lower the floor. The total data read per block increases (you’re loading the full BAL upfront), and the burst nature of the new pattern creates higher peak IOPS demand. Drives at 27,000 random read IOPS have the same fundamental problem, expressed differently: a burst bottleneck at block arrival rather than scattered stalls during execution.
The EIP-7870 floor remains the correct baseline post-Glamsterdam. The sustained 120 GiB/year state growth target that Glamsterdam aims for doesn’t reduce the minimum hardware needed to track chain head.4
Block explorer implications
A block explorer is a full node plus a parallel indexer. While a full node reads state during block validation and moves on, a block explorer simultaneously writes additional lookup structures: transaction indexes by address, event indexes, token transfer tables, storage diff records.
During steady-state operation, this roughly doubles write amplification compared to a plain full node. During initial sync or re-indexing, the load is higher , sustained high mixed read/write, not just reads.
The EIP-7870 floor is the minimum for a full node. A production block explorer should target roughly two times that headroom: 100,000 or more read IOPS is not over-specced when indexing runs in parallel with sync. The Kingston Fury Renegade class (211,000/70,000 IOPS) is the right tier for a production deployment.
When Ethernal runs alongside an active sync, performance varies between the initial sync phase and steady-state for this exact reason. During initial sync, the indexer and the sync process compete for the same I/O budget. On a drive at or near the EIP-7870 floor, one will slow the other down. Understanding the hardware characteristics explains behavior that would otherwise look like a software bug.
The practical conclusion
EIP-7870’s update exists because informal guidance created real failures. The word “NVMe” was precise enough to rule out SATA and spinning disk but not precise enough to rule out the large category of consumer NVMe drives that look fast on spec sheets and fail under Ethereum’s actual workload.
The fio random 4K benchmark is the only real answer to “will this drive work.” Run it before provisioning.
Glamsterdam (BALs, snap/2) improves I/O efficiency and eliminates the worst-case snap sync healing scenarios, but doesn’t reduce the storage hardware requirement. The 50,000-read-IOPS floor survives Glamsterdam intact.
If you’re operating an L2 and considering adding a block explorer alongside your node, plan for hardware above the full-node floor , not at it.
References
1. Barnabas Busa. “EIP-7870: Hardware and Bandwidth Recommendations for Ethereum Clients.” Ethereum Improvement Proposals, January 2025. https://eips.ethereum.org/EIPS/eip-7870
2. barnabasbusa. “Update EIP-7870: realistic minimum numbers.” GitHub / ethereum/EIPs, PR #11356, February 2026. https://github.com/ethereum/EIPs/pull/11356
3. Yorick Downe. “Good and bad SSDs for Ethereum nodes.” GitHub Gist, 2022-2026. https://gist.github.com/yorickdowne/f3a3e79a573bf35767cd002cc977b038
4. Ethereum Foundation. “Glamsterdam: Ethereum Roadmap.” ethereum.org, 2026. https://ethereum.org/roadmap/glamsterdam/
5. Go Ethereum team. “Hardware Requirements.” Geth Documentation, 2026. https://geth.ethereum.org/docs/getting-started/hardware-requirements
6. Nethermind team. “System Requirements.” Nethermind Documentation, 2026. https://docs.nethermind.io/get-started/system-requirements/