Fusaka-Devnet-5. A full node running at BPO2 parameters, 14 blobs per block as target. Network monitoring shows the execution client consuming 4 to 5x more bandwidth than the consensus client, for the same underlying blob data. Not a configuration error. Not a bug. This is how the blobpool was designed.
Since EIP-4844 shipped, the execution layer has stored and forwarded every blob sidecar it encounters in full. With 6 blobs per block at mainnet launch, that was manageable. Fusaka is scaling blob counts well beyond that. The math does not scale.
This is the Ethereum blobpool bandwidth problem. EIP-8070 (Sparse Blobpool) is the proposed fix, and it applies the same principle the consensus layer’s PeerDAS uses, custody-aligned sampling, to the execution layer’s mempool.
What the blobpool is and why it exists
An EIP-4844 blob transaction has two parts: the transaction itself (fees, target, version commitments) and the sidecar (blob data, KZG commitments, KZG proofs). For a blob transaction to be included in a block, block builders need the full sidecar before they can build. The blobpool stores these sidecars for pending transactions.
When a node sees a blob transaction announcement on devp2p, it fetches and holds the complete sidecar. This is full replication: every EL node that encounters a blob transaction downloads everything.
The per-block data load scales linearly with blob count:
| Blob count | Sidecar data per block |
|---|---|
| 6 (EIP-4844 launch) | approximately 768 KiB |
| 15 (Fusaka BPO1 max) | approximately 1.9 MiB |
| 21 (Fusaka BPO2 max) | approximately 2.7 MiB |
| 48 (future target) | approximately 6 MiB |
Each of those figures gets replicated across every peer connection in the network, for every pending transaction, before any block is built.
Two networks, one blob
Ethereum runs two separate P2P networks.1 The execution layer uses devp2p with RLPx-encrypted TCP connections. The consensus layer uses libp2p with gossipsub. They communicate locally via the Engine API, not over the P2P layer.
Blob transactions move through both networks at different stages.
Pre-inclusion (mempool): The EL handles blob transactions via devp2p using a three-phase protocol. NewPooledTransactionHashes announces the transaction. GetPooledTransactions requests the full object including sidecar. PooledTransactions delivers it, complete with blob data.
Post-inclusion (block gossip): The CL gossips blob sidecars on dedicated subnets (blob_sidecar_{subnet_id}). With PeerDAS (EIP-7594, shipping in Fusaka), the CL applies custody-aligned sampling: blob data is erasure-coded into 128 columns, each node custodies a deterministic fraction based on node ID, and any 64 of 128 columns are enough to reconstruct the full blob.2
The asymmetry is the problem. The CL already has sampling. The EL does not.
EthPandaOps measured this directly on Fusaka-Devnet-5.3 At BPO1 parameters (10 blobs target, 15 max), EL fetch rates ranged from 40 to 100 percent, meaning the execution client was fetching most blob data through its own blobpool rather than receiving it from CL gossip. At BPO2 parameters (14 blobs target, 21 max), the range was 20 to 90 percent with more variance. The raw bandwidth comparison:
| Node type | BPO1 receive peak | BPO2 receive peak |
|---|---|---|
| Supernode (>=4,096 ETH) | approximately 200 Mb/s | approximately 400 Mb/s |
| Validating node (32 ETH) | approximately 15-20 Mb/s | approximately 17-25 Mb/s |
| Full node (0 ETH) | approximately 4-8 Mb/s | approximately 8 Mb/s |
Average EL blobpool traffic ran 4 to 5x higher than equivalent CL blob gossip traffic. This gap widens as blob counts increase.
Why the consensus layer already has an answer
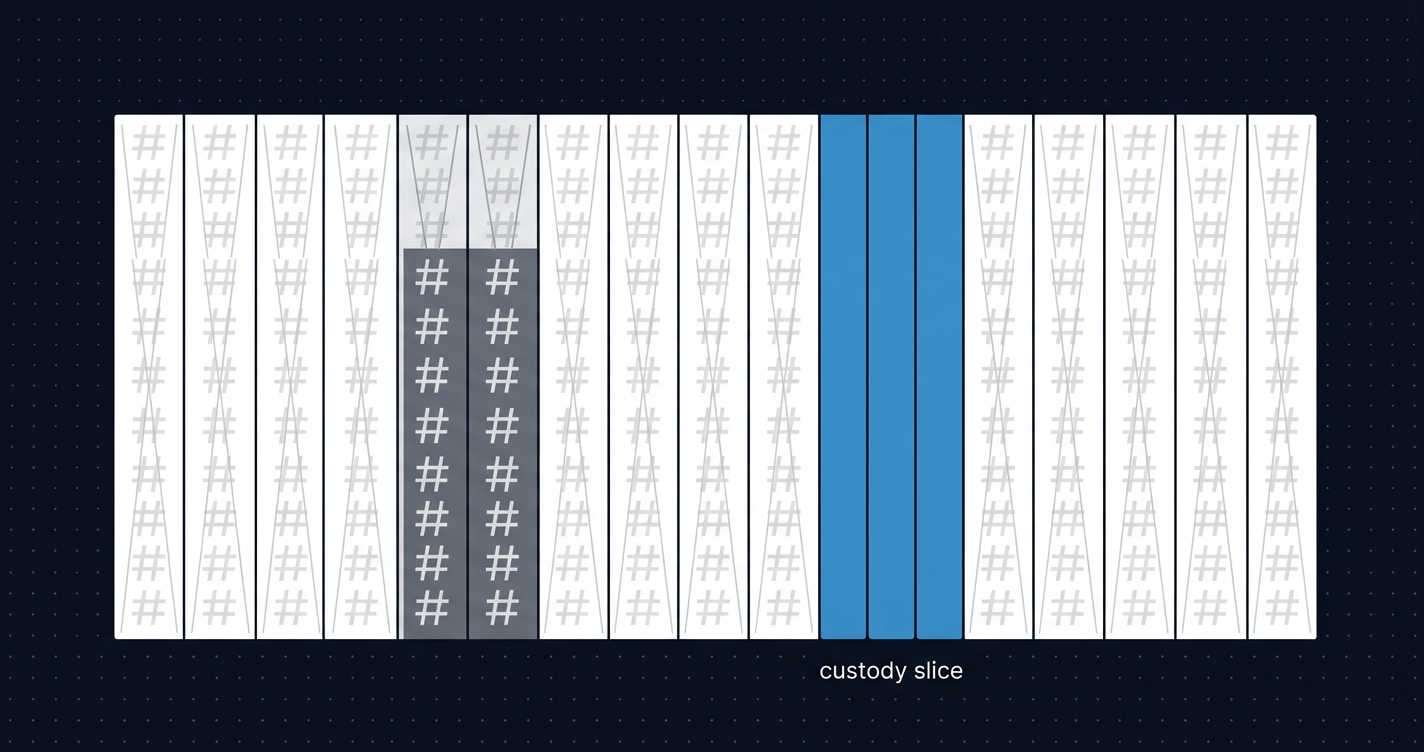
PeerDAS, included in Fusaka, solves the CL side of this problem.2 Blob data gets erasure-coded into 128 columns organized as gossip subnets. Each node custodies a deterministic subset determined by its node ID:
- Full nodes: 4 columns (approximately 3.1% of total data)
- Validating nodes: 8+ columns (approximately 6.25%)
- Supernodes: all 128 columns
Any 64 of 128 columns are sufficient to reconstruct the full blob. A node verifies availability by sampling columns from peers, not by downloading everything. The security properties are strong: with 10,000 nodes, an attacker controlling even 5% of the network has a success probability below 10^-306.2
This works because custody is deterministic and verifiable. You know which columns each node ID should hold. Misbehavior is detectable.
PeerDAS handles post-inclusion availability. The pre-inclusion mempool phase on the EL still uses full replication. That is the gap EIP-8070 addresses.
EIP-8070: custody sampling for the mempool
EIP-8070, authored by Raul Kripalani, Bosul Mun, Francesco D’Amato, Csaba Kiraly, Felix Lange, Marios Ioannou, Alex Stokes, and Kamil Salakhiev, proposes splitting EL nodes into two probabilistic roles.4
Providers (15% of nodes) fetch and hold the full blob payload and announce full cell availability to peers. Samplers (85% of nodes) fetch only their custody-aligned cells plus one random column and do not store or forward the full sidecar.
The bandwidth math is direct:
Current: 100% of all blob sidecar data per node
EIP-8070:
Providers (15% of nodes): 100% of sidecar
Samplers (85% of nodes): 12.5% = 1/8 of cells
Average per node: 0.15 x 100% + 0.85 x 12.5% = 25% -> 4x reductionThe protocol changes required:
NewPooledTransactionHashesgains acell_maskfield indicating which columns this node holds- Two new message types:
GetCellsandCells PooledTransactionsresponses omit full blob payloads (replaced with RLP nil values), since nodes now serve only what they hold- Engine API:
engine_getBlobsV4returns partial cells; block builders operate in eager mode and fetch all cells needed for inclusion engine_forkchoiceUpdatedV4gains acustodyColumnsparameter so the CL can tell the EL which columns it needs
The reliability numbers from the EIP:
>=3 of 50 mesh neighbors hold full payload: 98.6%
Reconstruction from sampler peers: 99.9%+
Total unavailability risk (D=50 mesh): 0.03%The fallback is straightforward: if fewer than 2 providers exist in a node’s local mesh (this occurs roughly 0.3% of the time at p=0.15), the node requests the full blob as before.
The Go-Ethereum team has built a working prototype.5 Internally, the Geth blobpool stores custody cells rather than full blobs. A new Blob Fetcher module schedules cell exchange in async or sequential modes. Peer scoring tracks transaction inclusion rates and request responsiveness, providing local defense against lazy or malicious providers.
Security concerns raised in Ethereum Magicians include “covert flash attacks,” where malicious nodes build reputation then coordinate misbehavior. The EIP’s counter is sampling randomization combined with actively seeking new peer connections. Eclipse attacks that block more than 50% of a blob’s columns are the harder case, and the fallback to full-blob fetching handles the most pathological scenarios.
The companion fixes: EIP-8077 and EIP-8094
Two proposals from Csaba Kiraly extend the same coordinated redesign of blob transaction propagation.
EIP-8077: transaction announcements with nonce6
The current NewPooledTransactionHashes message carries only hash, type, and size. Without sender address and nonce, a node receiving multiple announcements for the same transaction from different peers cannot do intelligent filtering. It risks fetching redundantly or creating nonce gaps in its local mempool view. EIP-8077 adds the sender address (20 bytes) and nonce to each announcement, enabling a node to skip fetching if it already holds a later nonce from the same sender.
EIP-8094: blob-aware mempool / eth/vhash7
Replace-by-fee for blob transactions currently re-distributes the entire sidecar across the network even when only the fee changed. RBF happens most during fee volatility, exactly when bandwidth is already most constrained. EIP-8094 introduces the vhash, a content-addressable identifier for blob data. If a node already holds the sidecar for a given vhash, it skips re-downloading on RBF. Two new message types handle the separation: GetPooledBlobs and PooledBlobs. EIP-8094 does not require a hard fork.
Together, the three proposals form a coherent set: EIP-8070 reduces baseline bandwidth 4x, EIP-8094 prevents bandwidth spikes during fee bumps, and EIP-8077 eliminates redundant fetch round-trips.
What this changes for infrastructure operators
Today, every full node stores and forwards approximately 100% of all pending blob sidecar data. After EIP-8070, most nodes will store roughly 12.5 to 15% of that data (their custody slice plus provider probability).
For L2 operators submitting blob transactions, the propagation path changes. A blob sidecar reaches block builders through a distributed cell-exchange mechanism rather than full-sidecar forwarding. The fallback guarantees availability even in edge cases, but timing may differ from today’s behavior.
For block explorer operators, pending blob transactions will look different in the mempool. Today, the full sidecar is locally available at any node that received the transaction. After EIP-8070, a node’s mempool view may contain only partial cell data for a pending blob. The committed blob hash remains observable through standard transaction fields. The sidecar content is what becomes partially distributed.
Ethernal’s blob viewer already surfaces committed blob hashes for included transactions via standard RPC. The pending-mempool case, where the sidecar exists but is distributed across sampler nodes rather than held in full locally, is where operators will notice the shift first.
EIP-8070 targets a post-Fusaka upgrade, likely Glamsterdam. PeerDAS ships first in Fusaka; the EL-side sampling follows. The Geth prototype and active discussion suggest it is moving forward.45
The bigger picture
The blobpool bandwidth problem is invisible until you run a devnet at scale. Fusaka-Devnet-5 made it visible: the execution layer’s full-replication blobpool is a 4 to 5x bandwidth amplifier relative to the consensus layer, and that ratio applies to a growing base as blob counts increase.
EIP-8070 applies custody-aligned sampling to the EL mempool. The math works: 4x average bandwidth reduction with 0.03% unavailability risk and a conservative fallback. The coordination across EIP-8070, EIP-8077, and EIP-8094 is a coherent redesign of how blob transactions move through the P2P network before they land in a block.
There is something quietly satisfying about this. The CL solved blob availability with PeerDAS. The EL is now catching up with the same idea, applied one layer earlier in the transaction lifecycle. When both sides use sampling, the bandwidth cost of blobs stops scaling linearly with node count. That is not a small thing as blob targets keep rising.
Frequently asked questions
What is the Ethereum blobpool?
The Ethereum blobpool is the execution layer’s mempool for EIP-4844 blob transactions. Unlike regular transactions, blob transactions include a sidecar containing blob data, KZG commitments, and KZG proofs. The blobpool stores complete sidecars for all pending blob transactions so block builders can access them during block construction. Currently, every EL node that receives a blob transaction downloads and forwards the full sidecar, a design called full replication.
Why does EIP-8070 reduce bandwidth by 4x?
EIP-8070 assigns nodes probabilistically to two roles. Approximately 15% become providers that hold the full blob payload. The remaining 85% become samplers that hold only their custody-aligned cells, approximately 1/8 of the total blob data. The average data per node works out to 0.15 x 100% + 0.85 x 12.5% = 25% of current load, a roughly 4x reduction.
What is the difference between the EL blobpool and PeerDAS?
PeerDAS (EIP-7594) applies custody-aligned sampling to the consensus layer’s post-inclusion blob gossip. The EL blobpool handles pre-inclusion blob storage in the mempool, which is a separate P2P network using devp2p. PeerDAS ships in Fusaka. EIP-8070 extends a similar sampling principle to the EL blobpool and is targeting a later upgrade, likely Glamsterdam.
When will EIP-8070 ship?
EIP-8070 targets a post-Fusaka upgrade. Fusaka, which includes PeerDAS, is Ethereum’s next major hard fork. After Fusaka, EIP-8070 is expected to be considered for Glamsterdam. The Go-Ethereum team has a working prototype and the proposal is under active discussion on Ethereum Magicians.
References
1. Ethereum Foundation. “The Ethereum Networking Layer.” ethereum.org, 2024. https://ethereum.org/developers/docs/networking-layer/
2. Ryan, Danny, Dankrad Feist, Francesco D’Amato, et al. “EIP-7594: PeerDAS - Peer Data Availability Sampling.” Ethereum Improvement Proposals, November 2024. https://eips.ethereum.org/EIPS/eip-7594
3. EthPandaOps. “Fusaka Bandwidth Estimation.” ethpandaops.io, 2026. https://ethpandaops.io/posts/fusaka-bandwidth-estimation/
4. Kripalani, Raul, Bosul Mun, Francesco D’Amato, Csaba Kiraly, Felix Lange, Marios Ioannou, Alex Stokes, and Kamil Salakhiev. “EIP-8070: eth/72 - Sparse Blobpool.” Ethereum Improvement Proposals, 2026. https://eips.ethereum.org/EIPS/eip-8070
5. Go-Ethereum Team. “Geth Statement on EIP-8070.” HackMD, 2026. https://hackmd.io/hJf45UjXTqikV5GqD5dR-Q
6. Kiraly, Csaba. “EIP-8077: eth/XX - Transaction Announcements with Nonce.” Ethereum Improvement Proposals, November 2025. https://eips.ethereum.org/EIPS/eip-8077
7. Kiraly, Csaba. “EIP-8094: eth/vhash - Blob-Aware Mempool.” Ethereum Improvement Proposals, November 2025. https://eips.ethereum.org/EIPS/eip-8094